This foundational course introduces participants to the core principles of data engineering, focusing on Hadoop and Spark technologies. Students will grasp the fundamentals of distributed computing, Hadoop's role in handling large-scale data, and Spark's capabilities for efficient data processing. From data storage to advanced analytics, this course provides hands-on experience in building robust data pipelines. By the end, learners will possess the essential skills to design, implement, and optimize scalable data solutions using Hadoop and Spark in real-world scenarios.
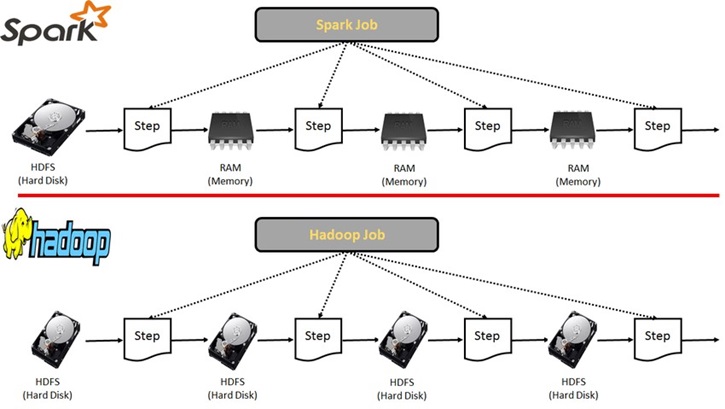
Basic programming skills, Familiarity with data concepts, Understanding of Linux commands.
20 hours of self-paced interactive learning, including summative assessment and expert live interactions
At the end of the course, the student will be able to:
![]() Proficient understanding of the Hadoop ecosystem for big data processing.
Proficient understanding of the Hadoop ecosystem for big data processing.
![]() Competency in programming with Pig and Spark for data analytics.
Competency in programming with Pig and Spark for data analytics.
![]() Effective skills in data storage and querying with relational and non-relational stores.
Effective skills in data storage and querying with relational and non-relational stores.
![]() Expertise in managing and optimizing Hadoop clusters for efficiency.
Expertise in managing and optimizing Hadoop clusters for efficiency.
![]() Practical application of learned concepts to design real-world data engineering systems.
Practical application of learned concepts to design real-world data engineering systems.
![]() In-depth knowledge of advanced Spark topics, including Spark SQL and cluster deployment
In-depth knowledge of advanced Spark topics, including Spark SQL and cluster deployment
© BITS - L&T EduTech , All Rights Reserved.
Designed by IT Services Unit BITS Pilani, Pilani Rajasthan.
Visitor Count -